A SPATIAL MODELING AND DECISION SUPPORT SYSTEM FOR CONSERVATION OF BIOLOGICAL DIVERSITY
Regional vegetation classification and mapping
AVHRR compositing strategy for generating a
multi-temporal data set
Map-guided classification for the Intermountain
Semi-Desert Ecoregion
Regional vegetation classification and mapping based on existing maps and satellite imagery. In our original proposal we posed this as a problem of map generalization to bring adjacent maps into consistent taxonomic and spatial detail, but we reformulated the problem as that of 1) selecting an existing vegetation classification system or developing a new classification that is better suited to regional conservation planning, and 2) creating a new regional vegetation map from remotely sensed imagery under guidance from existing subregional vegetation maps. We devised a new approach to image compositing to provide consistent, cloud-free remotely sensed data for the entire region throughout a growing season. A new approach for image classification that was also developed appears extremely promising not only for regional vegetation mapping but for monitoring as well.
Mapping the vegetation of the Intermountain Semi-Desert ecoregion required two new developments which are described below: a multi-temporal image data set that covered the entire region, and improved classification techniques for incorporating existing map information to assist in labeling the spectral clusters.
AVHRR compositing strategy for generating a multi-temporal data set
We selected NOAA Advanced Very High Resolution Radiometer (AVHRR) data for the multitemporal imagery because it is available on a daily basis over the entire growing season, allowing plant phenology to be incorporated in the classification.
Cloud cover is likely to be a problem in parts of any single AVHRR scene covering an area as large as the western U.S. Scene compositing methods are now routinely used to aggregate images acquired over 10-14 days into a single, cloud free image. During the course of our IBM research, we found that the standard compositing algorithm used by the U. S. Geological Survey, tends to be biased towards off-nadir viewing. This bias has the effect of blurring the spatial resolution of the data as well as adding atmospheric and surface reflectance effects. We have explored different methods of compositing that try to favor near-nadir views that also satisfactorily remove cloud effects.
There are three criteria to consider for the selection of the best pixels for the given composite period: pixels chosen would ideally have the minimum satellite zenith angle values, the maximum vegetation index values, and the maximum apparent temperature of all candidate pixels for a single pixel on the ground or geopixel. Each of these criteria has been shown to improve the quality of AVHRR composites. Both maximizing vegetation index and maximizing apparent temperature improve composites by choosing pixels with less atmosphere and clouds, while a smaller satellite zenith angle improves the consistency of the pixel resolution across the land surface. Therefore, a multiple objective approach was utilized.
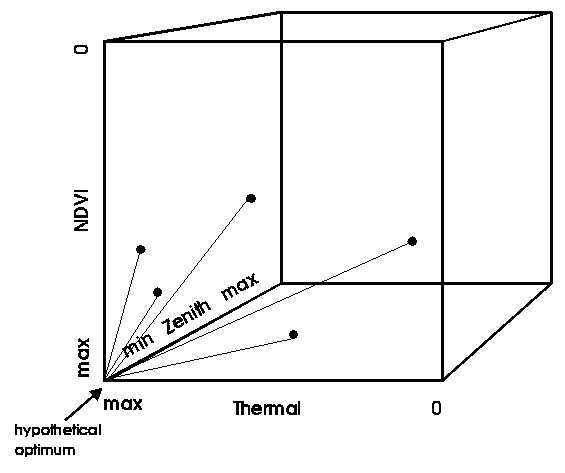
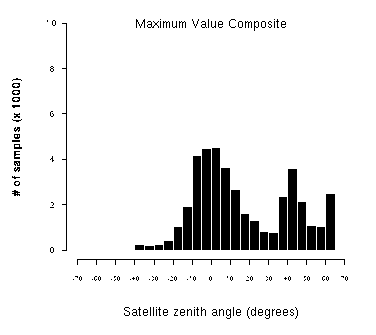
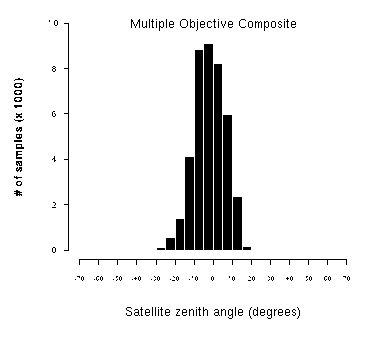
For any geopixel location, considering all candidate pixels for the composite period, the hypothetically optimal pixel has the highest vegetation index, highest apparent temperature and lowest satellite zenith angle. It is quite likely the hypothetically optimal pixel does not exist, however, but finding the pixel closest to this hypothetically optimal value maximizes the three objectives. In order to find the "best" pixel considering all three objectives, the multidimensional Euclidean distance of each pixel from each image is calculated, and the one with the shortest distance to the hypothetical optimum is chosen (Figure 4). Figure 5a and b contrasts the distribution of satellite zenith angles in the traditional Maximum Value Compositing method and our Multiple Objective Composite. The Multiple Objective Composite for the test period produced zenith angles much more concentrated around nadir viewing.
Figure 4. Diagram of a hypothetical AVHRR data set showing the distribution of pixel values from different dates in multidimensional space representing thermal DN, vegetation index (NDVI), and satellite zenith angle relative to a hypothetically optimal vector of values for that spatial location.
The three axes, of course, are in different units and it is necessary to scale each axis independently. Weights used for apparent temperature and NDVI were varied in all combinations of 0, .25, .5, .75 and 1 and satellite zenith angle of 0 0.1 and 0.2. The best preliminary compositing algorithm, based on a comparison with higher resolution Thematic Mapper imagery from the same compositing period in September, 1990, was with a high weight for apparent temperature, a small weight for satellite zenith angle, and no weight for the vegetation index. The algorithm with a case study application for California has been published as a journal article (Stoms et al. 1997).
| a) | b) |
 |
 |
We have found that the weighting scheme appears to work well over a larger region such as the Great Basin using data from several composite periods throughout the growing season. Similarly, it has been successful using recent AVHRR data acquired in Santa Barbara on the Pacific Coast where the full range of viewing angles are available for testing. We used this compositing strategy to develop time-series images of NDVI and spectral bands for classification of land cover in the Intermountain Semi-Desert Ecoregion.
Map-guided classification for the Intermountain Semi-Desert Ecoregion
Cartographers are often asked to compile land-cover maps of specific regions for which land-cover mapping already exists for smaller subsets of the region. The existing maps are rarely ideal for the assigned task because they may be outdated, use a classification schema designed for a different set of objectives from the current task, and/or are not at the desired spatial resolution. Sometimes several maps, perhaps covering the entire study area, will be available but have different temporal, thematic, and spatial properties from each other as well as from the target product. The two most commonly used options for dealing with existing maps are remapping and mosaicking. With the first option, the cartographer chooses to ignore the information in the original maps and to remap the area rather than attempting to resolve their differences. The second option is to mosaic the maps together, perhaps with some attempt to match their classification schema (i.e., "cross-walking") but retaining any mismatches that will likely occur at map boundaries. If the maps overlap, rules for determining the preferred map source must be identified. In addition the cartographer could do the cross-walking plus attempt to smooth or adjust the mismatches in polygon boundaries and thematic labeling at map edges (i.e., "edge-matching"). If the region is quite large, both options (remapping and edge-matching) can entail more effort than is practical. Remapping is a particularly unsatisfying option given that it ignores so much available, if imperfect, data. Merely cross-walking maps into a common schema may also be inadequate, not only for esthetic reasons, but also because the regional map may still lack the consistency necessary for the kinds of analyses for which it is being compiled. If the classification schema of the source maps are too incompatible, the cross-walk may only be reasonable at a grosser level of aggregation than is useful for the analysis.
The objective of a regional gap analysis is to evaluate the conservation status of cover types at the "alliance" level, as surrogates for biodiversity as a whole. Alliances are defined by the dominant canopy plant species. This is a more detailed classification than most regional-scale remote sensing applications that focus on structural rather than floristic differences. There has been concern about the feasibility of edge-matching state-level GAP maps to make a seamless regional land-cover map (Zube, 1994; DellaSala et al., 1996).
Initial examination of the state-level land-cover maps of the Intermountain Semi-Desert Ecoregion (Figure 6) in the western United States suggested that simply mosaicking them would not provide the consistent product needed for gap analysis. Some classes were too general, some too detailed. The spatial resolution varied considerably according to the mapping method and the remote sensing and ancillary data sources used. Mapping the region again but using a single method was considered an unacceptable alternative given the large investment in producing the state maps. The task then was to synthesize a regional map from the existing GAP state maps, improving the spatial and taxonomic consistency while maintaining their best information. The desired consistency refers not only to the vegetation classification but also to the spatial resolution of the map and to the absence of artificial seams at state boundaries created by independent mapping.
An innovative approach was developed for this research project using existing maps as training data for classifying NOAA Advanced Very High Resolution Radiometer (AVHRR) meteorological sensor data. The focus of the IBM-ERP sponsored research was to develop and apply this "map-guided classification" technique and to determine whether AVHRR data products could provide the desired spatial consistency and thematic detail. The generality of the technique makes it useful in similar applications for compiling land-cover maps. This effort marks one of the first applications of the proposed National Vegetation Classification Standards (NVCS; FGDC, 1996) at a regional mapping scale and therefore provides one test of the feasibility of implementing these standards in real-world situations.
Steps in the regional mapping for the Intermountain Semi-Desert Ecoregion include the following (see http://www.biogeog.ucsb.edu/projects/ibm/isdgap/gap.html for details):
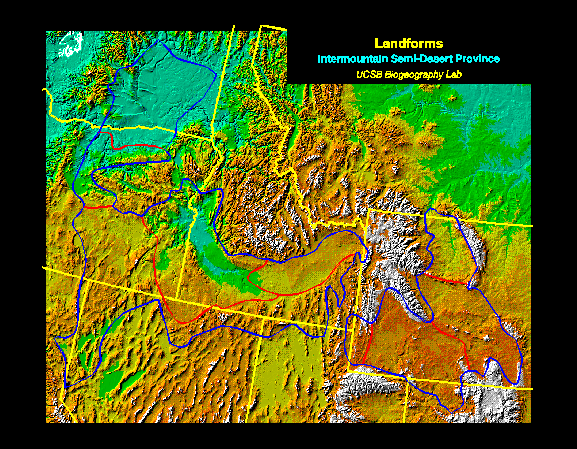
Figure 6. Shaded relief location map of the Intermountain Semi-Desert ecoregion showing the three subregions that were mapped independently.
Traditional multispectral mapping using satellite imagery involves a computer algorithm which forms statistical clusters in multidimensional space using some set of available spectral satellite bands. When the clusters have been formed, a human analyst can label each cluster using existing maps and knowledge about the landscape to create a per-pixel classified land cover map. As an alternative method to this manual cluster labelling, we have developed a procedure that iteratively combines the information from an existing land cover map with the cluster information. For each iteration, the satellite image is clustered. Clusters which have a high degree of association with a particular land-cover map class are labelled as that map class and eliminated from the satellite imagery. Those pixels that do not show a high degree of association with a land cover class are retained for future iterations until all pixels have been labelled. The iterative nature of this algorithm serves to identify and eliminate spectrally distinct clusters first to minimize the spread of variance in later iterations. This map-guided image classification technique can also be used to extend map information where there are no map data, or to join adjacent vector maps seamlessly across political borders based on their spectral information.
The map-guided classification procedure requires four basic steps. The state maps are cross-walked to a common land-cover classification; AVHRR time series data and elevation are preprocessed; the AVHRR and elevation data are classified using the cross-walked state maps as training data, and the output classified map is post-processed to deal with special cases.
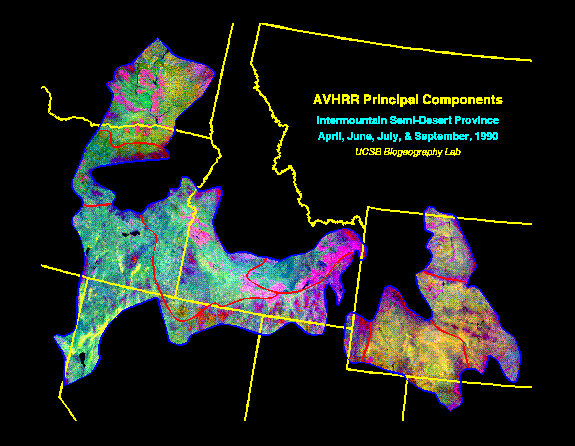
Figure 7. The first three AVHRR principal components of the Intermountain Semi-Desert ecoregion displayed as red-green-blue.
The AVHRR-derived datasets included band 2 (near infrared), band 4 (thermal infrared), and NDVI for each of the four composite periods (3 bands for each of the four dates). Principal components analysis was used to reduce the large, relatively correlated dataset (Cihlar et al., 1996; Hirosawa et al., 1996). Five of the principal components (Figure 7 shows a composite of the first three components), accounting for 85% of the variance in the twelve input channels, were then selected for use with the classifier. The AVHRR dataset provided a consistent, 1 km spatial resolution over the entire ecoregion.
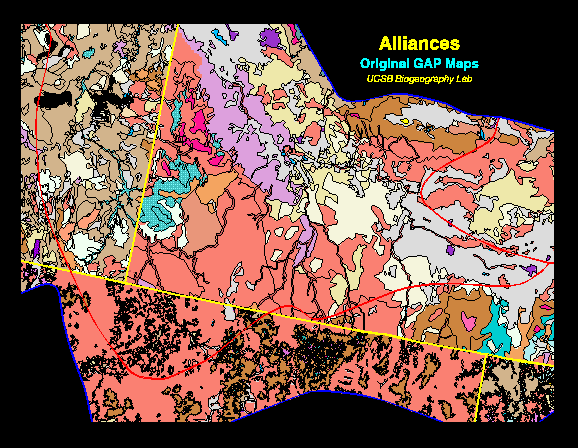
Figure 8. The original state GAP maps for a portion of the Idaho-Nevada boundary, illustrating the edge-matching problem.
The iterative, map-guided classification procedure used a standard maximum likelihood classifier in ARC/INFO GRID to assign pixels to information classes. The information classes and spectral clusters were compared, and the spectral cluster with the highest level of association (i.e., the highest ratio of pixels in a cluster and information class combination relative to the sum of pixels in the cluster in all classes) was assigned to its corresponding information class. The algorithm then removed the pixels in that spectral cluster from the dataset and repeated with the remaining data. The level of association from the first iteration was multiplied by .95, and this value was set as the threshold for assignment in the next iteration. If no cluster reached the threshold in subsequent iterations, the current highest association became the new threshold. Processing continued iteratively until all pixels were assigned to the alliance type that best matched their spectral signature or until a stopping rule was invoked. Based on initial runs, we decided to classify three subregions (the Columbia Basin, the southern Columbia Plateau, and the Wyoming Basin) independently to preclude types being extrapolated inappropriately to other subregions. The output map is virtually seamless across state lines as can be seen by comparing the original GAP maps (Figure 8) with the edge-matched version using map-guided classification (Figure 9) for an detail along the Idaho-Nevada boundary.
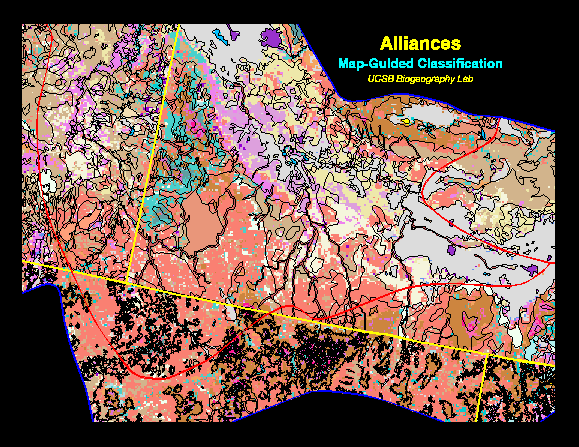
Figure 9. The edge-matched GAP map for a portion of the Idaho-Nevada boundary based on map-guided classification of AVHRR data.
The procedures, described in Stoms et al. (in review), successfully met the objectives to produce a seamless regional land-cover map at the alliance level. The multi-temporal AVHRR data provided consistent spatial resolution throughout the region and minimized the inconsistencies across state boundaries while preserving the best information in the source maps. Further improvement in accuracy is certainly possible. Based on the reviews from regional botanists, however, we believe the map-guided classification land-cover map is of sufficient quality to be useful for regional conservation assessment and for stratifying the ecoregion for detailed field survey.